What’s a token?
What will AI actually cost?
A token is a small chunk of text. It's also a unit of money — the thing AI is metered in.The word has been turning up a lot in our conversations with Chief Engineers and Commissioners, and everyone's asking: But what IS a token? Here’s what’s actually going on.
What a token actually is
When AI systems read or write language, they don’t operate on whole words. They operate on tokens — small chunks of text the model has been trained to handle. A short word like “the” is one token. A longer word might split into two or three tokens. Punctuation, capitalization, and rare words can each shift the count. A page of typical English prose comes out to roughly 500 tokens.
Tokens are what the model sees. They’re also what the model bills.
The companies that train these systems — Anthropic, OpenAI, Google — set their prices in dollars per million tokens, separately for input (what the AI reads) and output (what it writes). Every interaction with the model consumes tokens in both directions.
That’s the whole concept. And the math gets interesting at scale.
The unit cost is small.The multiplier isn’t.
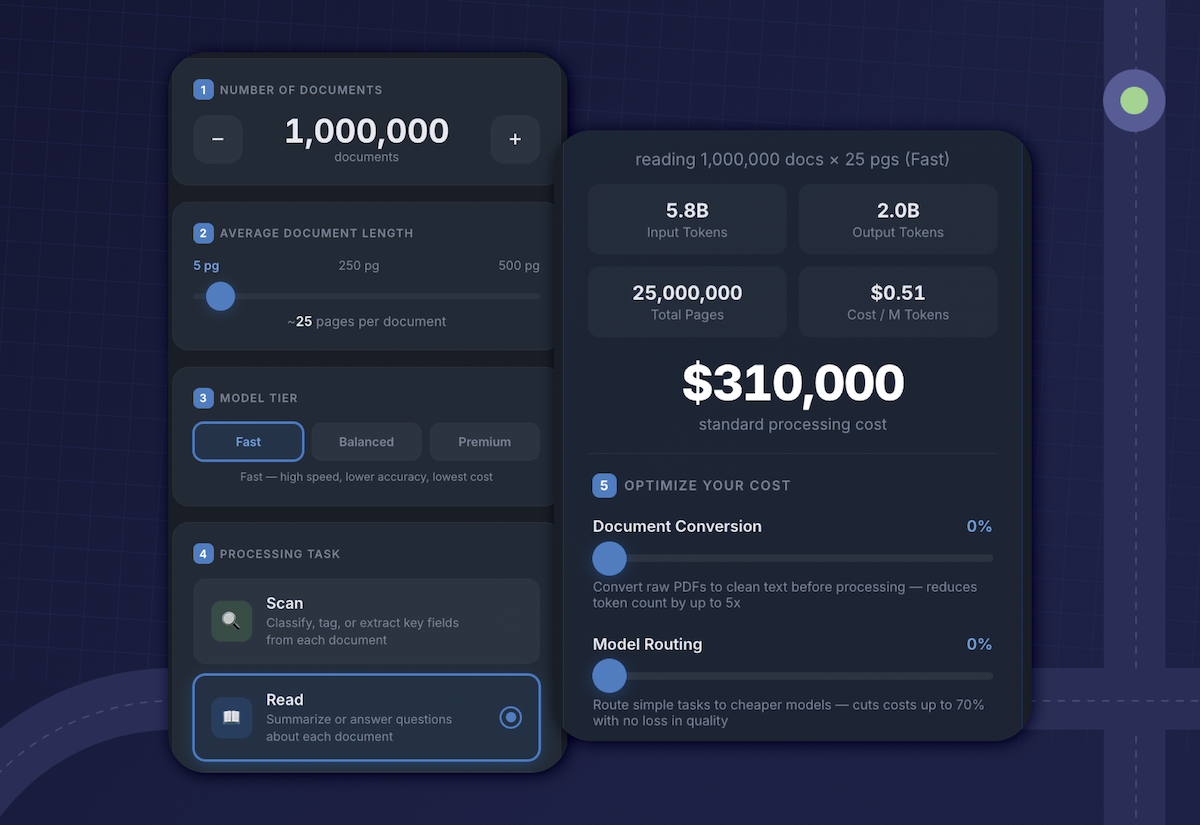
A single token, on its own, is essentially free. A short chat exchange with a frontier model costs pennies. A summary of a long document might run to a quarter. None of those are numbers a finance team would notice in isolation.
But AI rarely gets used in isolation. A document repository at a state agency might hold ten million files. Pointing an AI system at that corpus to extract structured data, even once, is real money. Letting a few hundred users start asking questions of those documents — where each question quietly pulls dozens of pages of context into the model — multiplies it again. The financial picture between a 10-document pilot and a full deployment isn’t 100 times larger. It’s often more.
This isn’t a warning. It’s just what happens when the pricing is per use, and the use scales fast.
AI bills aren’t cloud bills
Cloud computing taught a generation of leaders that data infrastructure costs can move in surprising directions.
Surprise cloud bills are a known shape now — usage scaled past projection, an environment got left running, an export ran longer than anyone expected. One DOT we spoke with got hit with an unexpected ~$1M cloud bill from a vehicle-data program. Stories like that aren’t rare.
AI is going to produce its own version of those stories, with different timing.
In a typical cloud workload, money is spent gradually as servers run and data moves. There’s some delay between a usage spike and the bill it produces. AI is more direct. Tokens are consumed as users type. A change in usage shows up almost immediately, and a change in scope —pointing the system at a much larger data set, for example — can produce a step-function jump in cost over the course of a single project cycle.
A small DOT we spoke with recently bought a pack of Microsoft Copilot credits. They burned through them in weeks, just from ordinary day-to-day use. That’s the canary. The signal is small now. The same shape gets large quickly.
“I have ChatGPT” and “we have AI” are not the same thing
A useful way to think about AI systems is to separate them into three layers. The writer Ethan Mollick has popularized this framing, and it earns its keep across budgeting, procurement, and ordinary conversation about what an AI tool actually is.
The model is the underlying engine — Claude, GPT, Gemini. It does the math on language. By itself, the model knows nothing about the work, the data, or the context of any specific organization.
The app is what someone interacts with— ChatGPT, Claude.ai, Copilot, or any custom interface built on top of a model.The app handles the conversation, the file uploads, the short-term memory. It’s still general-purpose.
The harness is everything that connects the model and app to actual organizational work. The integrations into systems where the documents live. The rules that route a query to the right model at the right cost. The test sets that catch when output quality drifts. The audit log that records what was generated and by whom. The harness is what turns a general-purpose AI into something an institution can rely on.
A consumer subscription gets you a model and an app. Consumer tools are great at what they do. The point is that the gap between “I have a ChatGPT account” and “my organization is running AI at scale” is much larger than it looks from the outside, and most of the gap is the harness.
Who pays who
Model providers are paid by the token. They have a real and reasonable interest in usage going up. They’re also the ones who decide how many tokens a given task will consume — and as models get more capable, they sometimes use more tokens to do the same job. That has happened in recent releases.
None of this is a story about bad actors. It’s the normal shape of a metered market. Twenty years ago, brands buying digital ads on platforms like Facebook eventually realized something simple: they couldn’t ask Facebook to manage their spend on Facebook. The platforms had every reason to be helpful, and many were. But the structural conflict was real, and the market grew an independent measurement and optimization layer to sit between the buyer and the platform.
AI is likely to follow the same path. Tools that route queries to the cheapest model that meets a quality bar, that track per-document and per-user spend, that flag unusual patterns — those tools work best when they aren’t built by the company being measured.
What’s worth asking
When evaluating an AI tool, a handful of questions tend to surface the real shape of what’s being sold. They aren’t gotchas. They just produce more useful conversations.
What does a typical query cost?
How does cost scale from a small pilot to a full deployment?
Can the system route between models based on the difficulty of the query? Routing — sending easy work to a smaller, cheaper model and reserving the expensive model for harder cases — is one of the most meaningful cost-control techniques in production AI today.
What does cost reporting look like, and on what cadence?
The point of these questions isn’t to test the vendor. It’s to find out whether they’ve done the work.
We’re early
In 2001, around 140 million people were online and roughly 85% of them were on dial-up. The web of that period was real, but the conventions, contracts, and cost models that would eventually make cloud computing routine were still in front of us. Nobody then was budgeting for serverless functions or pay-per-millisecond compute. Those things didn’t exist yet.
AI is at a similar moment. The tooling for token budgeting, model routing, quality measurement, and cost visibility is improving fast, but most of the patterns that will eventually feel obvious are still being worked out. The organizations getting useful results today are the ones treating that uncertainty as a normal feature of a young technology, not as a problem to wait out.
A token is a small thing. Understanding the unit, the math, and the layers around it is most of what’s needed to start thinking clearly about the rest.
TRY OUR TOKEN CALCULATOR
_________________________________________________________________
Beacon writes about how AI is actually used inside large institutions, at scale.
Emphasize your product's unique features or benefits to differentiate it from competitors
In nec dictum adipiscing pharetra enim etiam scelerisque dolor purus ipsum egestas cursus vulputate arcu egestas ut eu sed mollis consectetur mattis pharetra curabitur et maecenas in mattis fames consectetur ipsum quis risus mauris aliquam ornare nisl purus at ipsum nulla accumsan consectetur vestibulum suspendisse aliquam condimentum scelerisque lacinia pellentesque vestibulum condimentum turpis ligula pharetra dictum sapien facilisis sapien at sagittis et cursus congue.
- Pharetra curabitur et maecenas in mattis fames consectetur ipsum quis risus.
- Justo urna nisi auctor consequat consectetur dolor lectus blandit.
- Eget egestas volutpat lacinia vestibulum vitae mattis hendrerit.
- Ornare elit odio tellus orci bibendum dictum id sem congue enim amet diam.
Incorporate statistics or specific numbers to highlight the effectiveness or popularity of your offering
Convallis pellentesque ullamcorper sapien sed tristique fermentum proin amet quam tincidunt feugiat vitae neque quisque odio ut pellentesque ac mauris eget lectus. Pretium arcu turpis lacus sapien sit at eu sapien duis magna nunc nibh nam non ut nibh ultrices ultrices elementum egestas enim nisl sed cursus pellentesque sit dignissim enim euismod sit et convallis sed pelis viverra quam at nisl sit pharetra enim nisl nec vestibulum posuere in volutpat sed blandit neque risus.
Use time-sensitive language to encourage immediate action, such as "Limited Time Offer
Feugiat vitae neque quisque odio ut pellentesque ac mauris eget lectus. Pretium arcu turpis lacus sapien sit at eu sapien duis magna nunc nibh nam non ut nibh ultrices ultrices elementum egestas enim nisl sed cursus pellentesque sit dignissim enim euismod sit et convallis sed pelis viverra quam at nisl sit pharetra enim nisl nec vestibulum posuere in volutpat sed blandit neque risus.
- Pharetra curabitur et maecenas in mattis fames consectetur ipsum quis risus.
- Justo urna nisi auctor consequat consectetur dolor lectus blandit.
- Eget egestas volutpat lacinia vestibulum vitae mattis hendrerit.
- Ornare elit odio tellus orci bibendum dictum id sem congue enim amet diam.
Address customer pain points directly by showing how your product solves their problems
Feugiat vitae neque quisque odio ut pellentesque ac mauris eget lectus. Pretium arcu turpis lacus sapien sit at eu sapien duis magna nunc nibh nam non ut nibh ultrices ultrices elementum egestas enim nisl sed cursus pellentesque sit dignissim enim euismod sit et convallis sed pelis viverra quam at nisl sit pharetra enim nisl nec vestibulum posuere in volutpat sed blandit neque risus.
Vel etiam vel amet aenean eget in habitasse nunc duis tellus sem turpis risus aliquam ac volutpat tellus eu faucibus ullamcorper.
Tailor titles to your ideal customer segment using phrases like "Designed for Busy Professionals
Sed pretium id nibh id sit felis vitae volutpat volutpat adipiscing at sodales neque lectus mi phasellus commodo at elit suspendisse ornare faucibus lectus purus viverra in nec aliquet commodo et sed sed nisi tempor mi pellentesque arcu viverra pretium duis enim vulputate dignissim etiam ultrices vitae neque urna proin nibh diam turpis augue lacus.



